SynthonOR is a small open-source Python package for synthon similarity search. The central idea is deliberately minimal: represent synthons with standard RDKit-compatible fingerprints, combine them with a binary OR, and search for reaction-grounded candidate products without relying on a fully enumerated product catalog.
What makes the project interesting is not extra modeling complexity, but the opposite. Unlike SynthonGPT, there is no AI model here. Unlike systems such as SpaceLight, Hyperspace, or FTrees, the method is not built around connector-specific tricks, fragment heuristics, topological surrogate representations, or hand-crafted assembly logic. It is meant as a transparent “pure fingerprints” baseline for synthon-space retrieval.
Why it matters
- Easy to explain. The retrieval signal comes from familiar bit fingerprints and a simple OR composition rule.
- Easy to reproduce.
synthonorships with a bundled example synthon slice, a CLI, and benchmark scripts that can be run from the repo root. - Still practically useful. Even with the stripped-down design, the early benchmark signal is encouraging on difficult ChEMBL-like queries.
What ships today
SynthonOR currently supports multiple RDKit fingerprint families, including ecfp4, ecfp6, rdkit, topological_torsion, atom_pair, and patternfp. The package can be used either from Python or from the command line, and it includes a bundled example database (synthon_space_1M.tsv) for quick experiments.
from synthonor import (
build_synthon_fingerprint_cache,
example_space_path,
load_synthon_or_index,
search_smiles,
)
data_path = example_space_path()
cache_info = build_synthon_fingerprint_cache(data_path)
index = load_synthon_or_index(data_path)
hits = search_smiles(
"CCOc1ccc(NC(=O)N2CCN(CC2)C)cc1",
index,
top_n=25,
)
print(cache_info.cache_prefix)
print(hits[0].reaction_id, hits[0].synthon_ids, round(hits[0].approx_score, 3))
For command-line usage, the same workflow stays compact:
pip install synthonor
synthonor path/to/syntons.tsv \
--query "CCOc1ccc(NC(=O)N2CCN(CC2)C)cc1" \
--top-n 25 \
--output synthonor_hits.jsonl
Benchmark snapshot
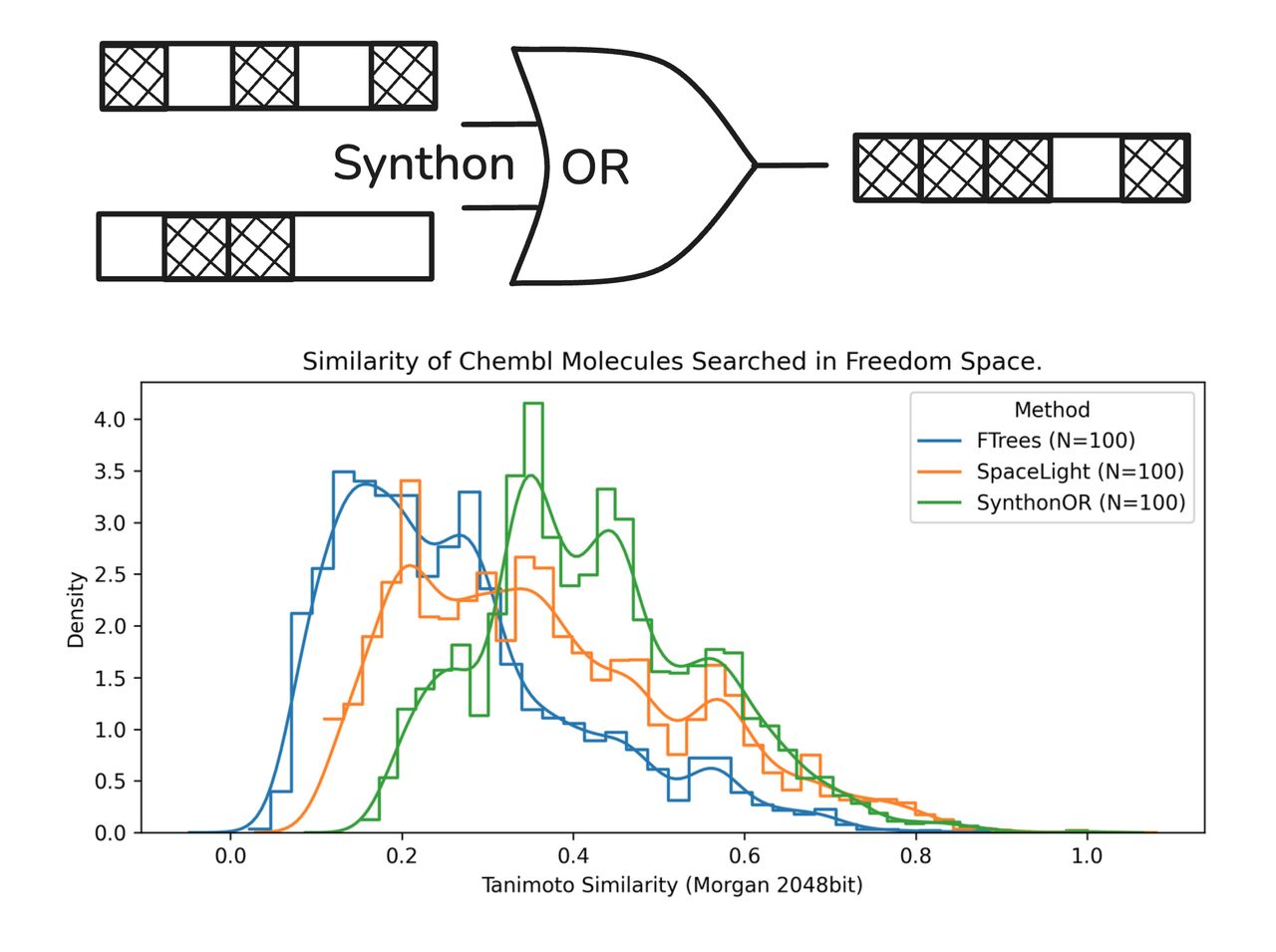
On the chembl_33_100 benchmark slice, 100 ChEMBL queries were searched against FreedomSpace_140bn_2025-07, and exact Morgan 2048-bit Tanimoto similarities were recomputed on the returned products for a count-matched comparison. On this slice, SynthonOR shifts clearly to the right of SpaceLight and FTrees, with a mean count-matched similarity of 0.427, compared with 0.371 for SpaceLight and 0.266 for FTrees.
That is especially interesting because the query set includes awkward molecules such as peptides and macrocycles. The point is not that SynthonOR solves everything, but that a method this simple can already be competitive enough to serve as a strong, interpretable baseline.
Links
- Demo: synthonor.mireklzicar.com
- GitHub: Deep-MedChem/synthonor
- PyPI: pypi.org/project/synthonor